The Final Bridge
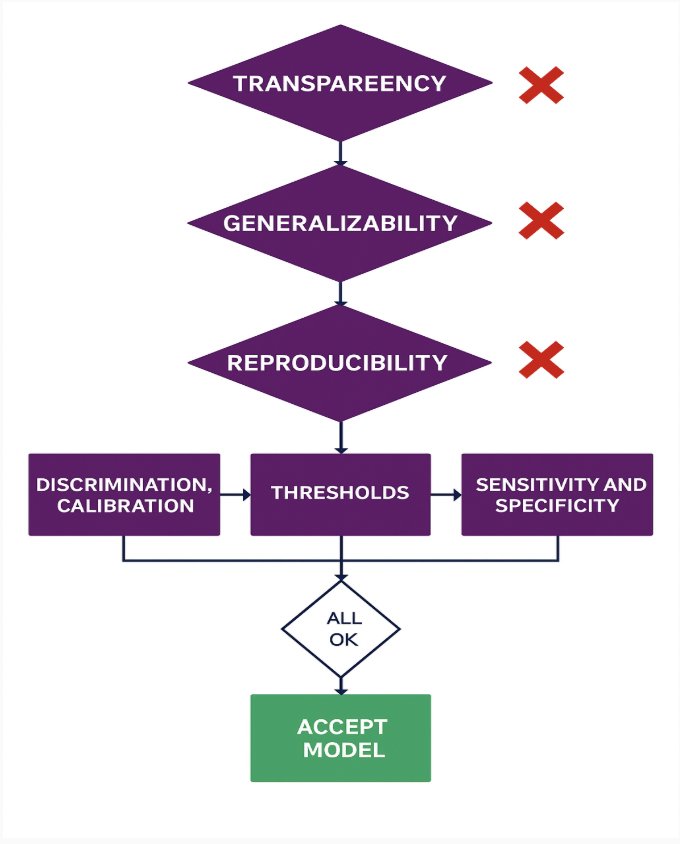
We have explored the technical depths of discrimination, calibration, and threshold selection. We have examined the rigorous demands of transparency and reproducibility. Now, we must ask the final question: Why does this matter?
It is not just about better math. It is about building a healthcare system that works. Evaluating AI’s true clinical impact requires moving beyond surface-level metrics toward a system-wide view of reliability, reproducibility, and real-world validity.
Statistics Are Trust Indicators
Discrimination, calibration, and threshold selection aren’t abstract statistics—they are clinical trust indicators.
Every time a model is calibrated correctly, a clinician gains confidence. Every time a threshold is set transparently, a patient is protected. Conversely, when transparency gaps obscure the rationale, reproducibility lapses create inconsistent AUCs, or calibration drifts across populations, that confidence is shattered.
The Strategic Mandate
Healthcare organizations cannot afford to treat evaluation as an afterthought. They must establish frameworks that connect algorithmic performance directly with operational integrity and patient outcomes.
This is the strategic imperative: We must stop asking “Does the model work in the lab?” and start asking “Does the system work for the patient?”
Conclusion: The Win–Win–Win
Only by measuring what matters can we ensure AI’s promise translates from pilot to practice. This is how we move beyond “point solutions” to achieve a genuine win–win–win for patients, clinicians, and healthcare systems.
Authored By: Padmasri Bhetanabhotla



