Introduction: The Paradox of Optimization
In the final stages of the AI pipeline, we encounter a counter-intuitive reality. We often assume that giving an AI more information about a patient—like their age, sex, or race—will automatically make it “fairer.”
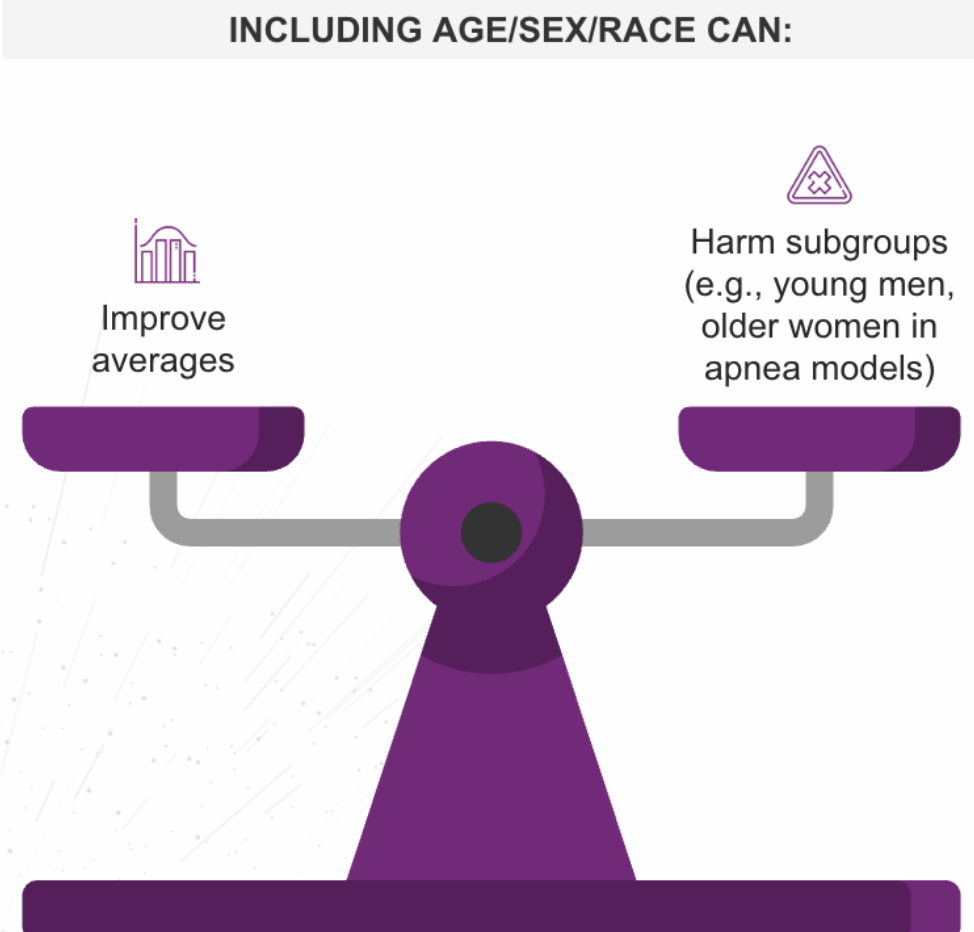
However, Stage 3 of our pipeline analysis reveals the Group Attribute Paradox: including demographic attributes can improve overall accuracy while simultaneously worsening outcomes for specific subgroups.
Stage 3: The Group Attribute Paradox
Consider a sleep-apnea model designed to predict risk. When developers added sex and age as variables, the model’s average performance across the entire population improved. It looked like a success.
But a closer audit revealed a hidden failure: while the averages went up, the model actually began performing worse for younger men and older women.
Why does this happen?
- Model Misspecification: The algorithm may miss complex interaction effects (e.g., how symptoms present differently in older women vs. younger men).
- Optimization Bias: The math is tuned to maximize the “aggregate score.” If the majority group improves significantly, the math doesn’t “care” that a minority group dropped slightly. The average still looks good.
The Solution: Fair Use Auditing We cannot simply guess whether to include demographics. We must rigorously compare three model types during development:
- Group-Blind: The model sees no demographics.
- Decoupled: Separate models are trained for separate groups.
- Group-Aware: The model includes demographics as variables.
Each approach has trade-offs. There is no universal “right” answer; there is only context-specific review.
Stage 4: Post-Deployment and the “Crisis Line” Lesson
Even if the algorithm is perfect, bias can re-emerge in Stage 4: Integration Design.
How we present information to a clinician matters as much as the quality of the model. A landmark study on mental health crisis lines illustrates this perfectly.
- Prescriptive Bias (The Failure): When the AI gave a direct command—“Call the police”—users followed the advice, amplifying the underlying bias in the training data.
- Descriptive Mitigation (The Success): When the AI was changed to only flag a “risk of violence” (without a command), the bias disappeared.
Key Lesson: When the AI stopped being a “boss” and started being an “informant,” the humans used their own judgment to correct the bias.
Mitigation Tactics: Interface Over Algorithm
Post-deployment interface design can often prevent bias amplification more effectively than pre-deployment algorithm tweaks. To ensure safety, organizations should:
- Use Descriptive Flags: Avoid directive commands (“Do this”). Instead, use descriptive alerts (“High risk of X detected”) to trigger human judgment.
- Provide Context: Don’t just show a score; show why the score is high.
- Train Clinicians: Staff must be trained on “AI-bias awareness”—understanding that the machine has blind spots just like a human does.
Conclusion: Safety is a Design Choice
Bias is not just a data problem; it is a design problem. From the mathematical paradoxes of Stage 3 to the user interface choices of Stage 4, ensuring equity requires intentionality. By designing workflows that empower human judgment rather than replacing it, we can silence the “echo chamber” of bias and ensure AI serves every patient equitably.
Authored By: Padmasri Bhetanabhotla



